DuckDB Internals: Why Is DuckDB Fast? (Part 1)
DuckDB Internals: Why Is DuckDB Fast? (Part 1)
By Kyle Cheung / May 4, 2026 / 18 min read
Since its inception as a research project at CWI Amsterdam in 2019, DuckDB has evolved into one of the most influential databases of the last decade. Its footprint is everywhere:
- Interactive notebooks and ETL pipelines.
- Business intelligence dashboards and CI test runners.
- Embedded analytics within SaaS platforms.
Even an iPhoneActually, an iPhone running TPC-H at scale factor 100!

Real-World Adoption
Industry leaders are now integrating DuckDB directly into their product architectures:
- Hex, Omni, and Evidence: Utilize it as a high-performance cache and in-app execution engine.
- Fivetran: Employs DuckDB within its Managed Data Lake Service for compaction and merging tasks.
- Greybeam: We rely on it to power millions of analytical and BI queries.
What does "Analytical" actually mean?
DuckDB is an analytical engine. This means it is specifically tuned for queries that scan millions of rows to perform joins, filters, and aggregations. It is not designed for transactional workloads (like looking up a single user record by a primary key).
Unlike traditional databases, you don't "connect" to a DuckDB server. Instead, you import it as a library—similar to how you would use NumPy or Polars.
The Secret to its Popularity: Frictionless UX
DuckDB's explosion in popularity is largely due to its extreme ease of use:
- Lightweight: A single binary under 20 MB with zero external dependencies.
- Easy Installation:
pip install duckdbbrew install duckdb- Linking
libduckdbinto C++ projects.
- Flexible I/O: It can treat directories of JSON, CSV, or Parquet files as if they were native SQL tables.
Despite its simplicity, it is one of the fastest single-node engines available, often competing with massive, multi-million dollar clusters.
Roadmap: A Three-Part Deep Dive
This is the first installment of a series tracing a query's journey from input to result.
Our goals for this series:
- Part 1: SQL Execution Readiness & Storage Layout.
- Part 2: The Execution Engine (Subscribe to find out!).
- Part 3: Final Optimization and Result Delivery.
The Pillars of DuckDB's Speed
DuckDB achieves its performance through several critical design choices:
- In-process execution (No network overhead).
- Columnar storage (Compressed with zonemaps).
- Vectorized execution (Processing batches of data).
- Morsel-driven parallelism (Efficient multi-threading).
- Snapshot isolation (via optimistic MVCC).
The Power of In-Process Execution
Consider a scenario where you query a 6 GB Parquet file on your local machine:
SELECT * FROM 'orders.parquet';
The "Server" Problem
Most analytical databases operate as remote servers. The workflow looks like this:
Client Server Client
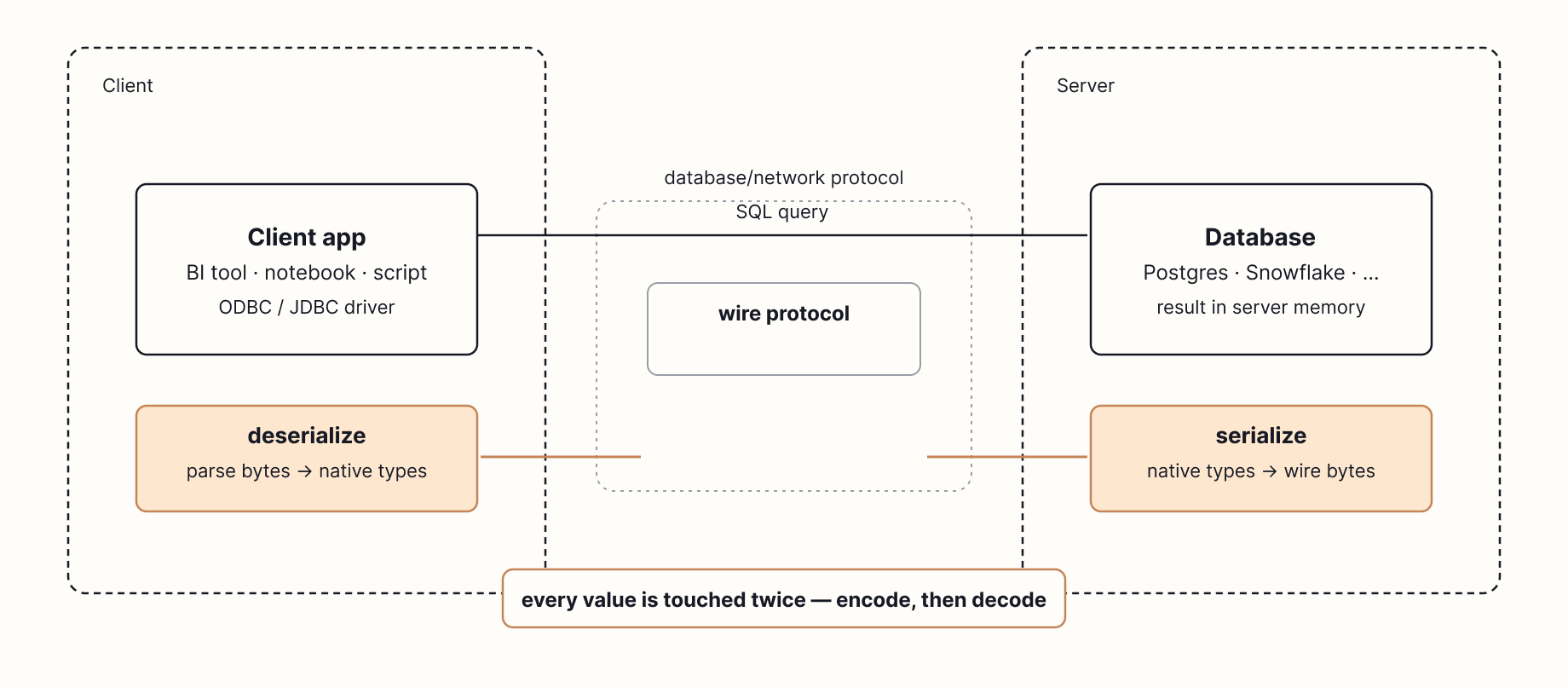
This architecture introduces a massive bottleneck: Serialization and Deserialization.
The "Data Hostage" Problem In 2017, Mark Raasveldt and Hannes Mühleisen published "Don't Hold My Data Hostage," revealing that the client protocol (ODBC/JDBC) is often the slowest part of a query, sometimes taking longer than the actual computation.
Why is this slow?
| Bottleneck | Description |
|---|---|
| Bandwidth | A standard gigabit link is capped at . Large results take forever to move. |
| API Overhead | ODBC/JDBC fetch results row-by-row, value-by-value. |
| CPU Waste | 100M rows hundreds of millions of function calls, memory copies, and type checks. |
The Alternative: ADBC The Arrow Database Connectivity (ADBC) API improves this by transferring data in a columnar Arrow format, bypassing row-based serialization.
The DuckDB Approach: Zero-Distance
DuckDB eliminates these issues by living inside your program. There is no TCP socket, no wire protocol, and no remote server.
Replacement Scans and Zero-Copy
When you run a query against a pandas dataframe (e.g., FROM my_df), DuckDB uses a replacement scan. Instead of importing the data into its own internal tables, it replaces the table reference with a function that reads the dataframe directly.
If the physical memory layout matches (e.g., a NumPy buffer of int64 values), DuckDB can read that memory directly.
- Best Case: Truly zero-copy.
- Worst Case: If types or null representations differ, DuckDB allocates converted buffers.
Apache Arrow is the gold standard here because it is a columnar, typed memory format specifically designed for this kind of cross-system sharing.
From SQL to Logical Plan
Once the SQL string enters the engine, it undergoes a standard transformation pipeline:
Parse Bind Plan Optimize
1. Parsing
The first phase is Parsing, where the raw SQL text is converted into an Abstract Syntax Tree (AST).
(Note: The detailed breakdown of binding and planning continues in the subsequent sections of the internal deep dive...)