Two Qwen3 models on one DGX Spark: the residency math
Two Qwen3 Models on One DGX Spark: The Residency Math
By Devashish | June 16, 2026
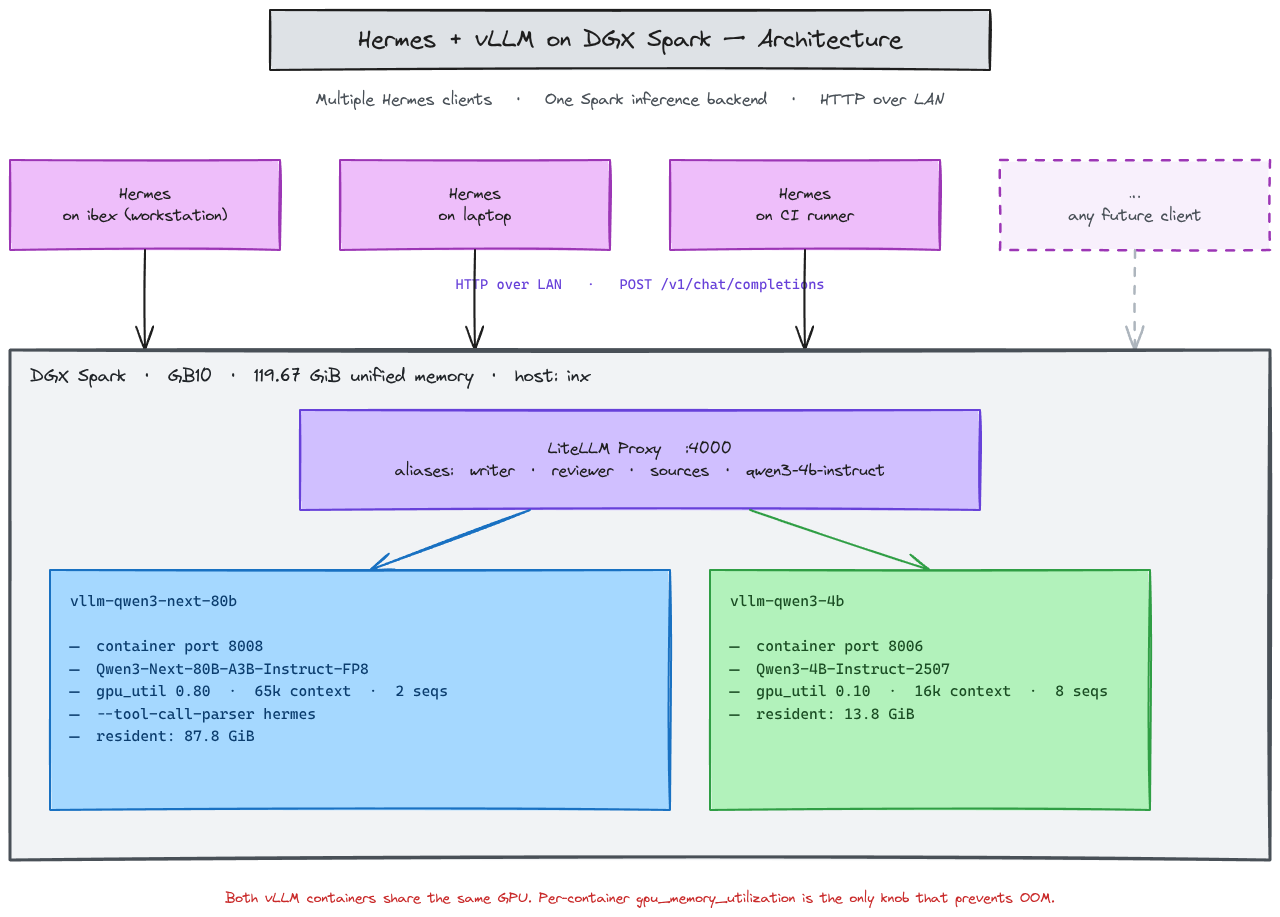
My current agent stack, powered by Hermes, operates on a split architecture. To ensure the workstation remains responsive, I offload the heavy GPU lifting to a DGX Spark, with the two communicating via an HTTP proxy.
As I've scaled my agent fleet using Clawrium, the number of Hermes instances has grown. This has shifted the workload from a simple "one-laptop, one-model" setup to a fleet of agents hammering a single backend—a traffic pattern that a standard single-model server simply cannot handle.

The Infrastructure Goal
For months, the Spark served models via ollama. However, ollama lacks granular control: there is no per-process memory budget and no gpu_memory_utilization toggle. This makes it nearly impossible to co-reside a "heavy" reasoning model alongside a "fast" model for quick interactions.
While llama.cpp (the backend) uses PagedAttention to reclaim KV blocks rather than pinning contiguous memory, I needed more control. My target setup:
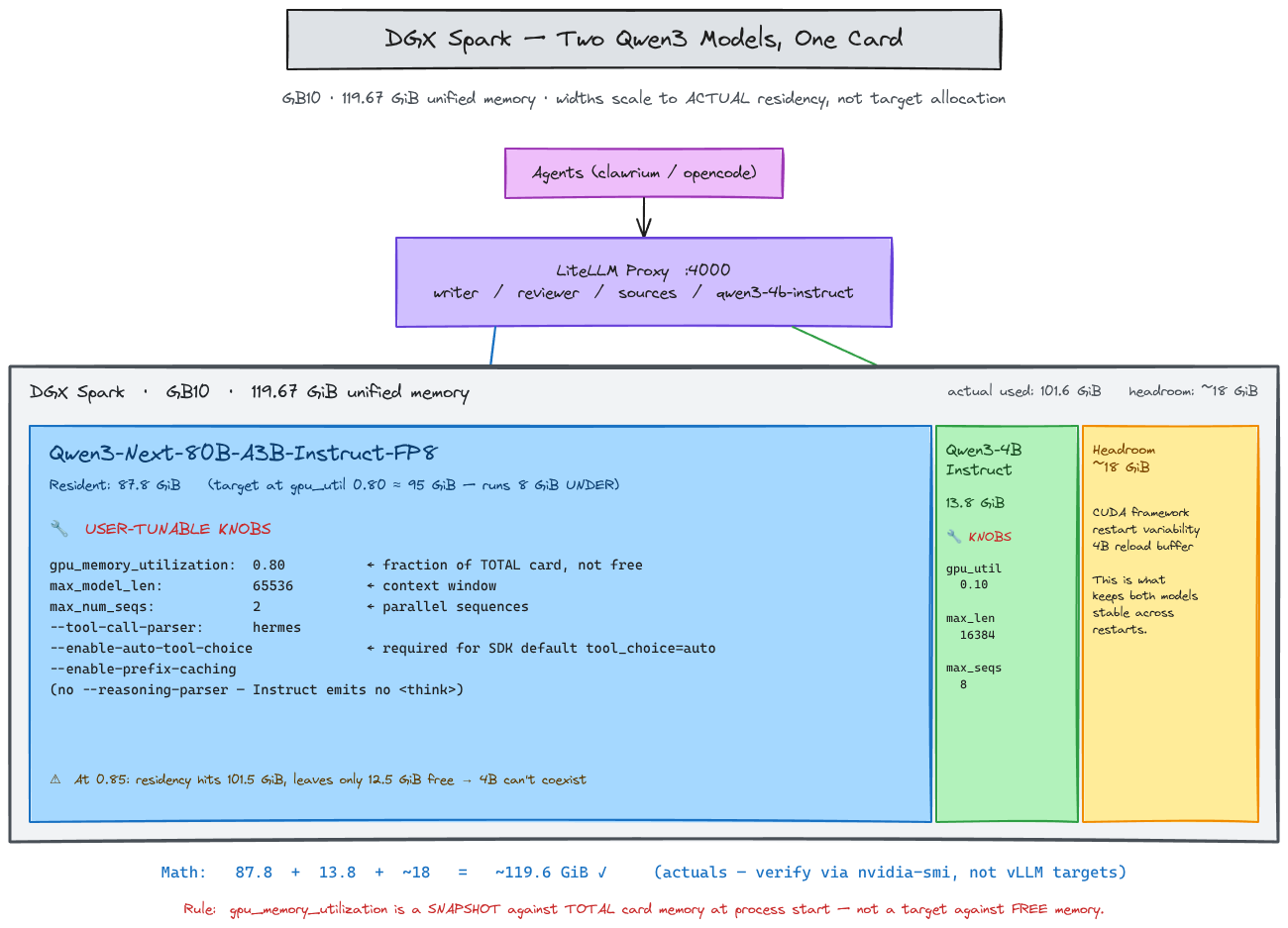
- Hardware: One DGX Spark (GB10) with of unified memory.
- Software: Multiple vLLM containers orchestrated by a LiteLLM proxy on port
:4000. - Models:
Qwen3-Next-80B-Instruct-FP8(The "Heavy Lifter")Qwen3-4B-Instruct-2507(The "Fast Responder")
The Trial and Error Process
Attempt 1: The gpu_memory_utilization Trap
I started by trusting the target configurations. For the 80B model, I set:
gpu_memory_utilization: 0.75max_model_len: 65536max_num_seqs: 4
The Result: vLLM crashed during KV cache initialization with: "No available memory for the cache blocks."
Because Qwen3-Next is primarily a Mamba-based architecture, the per-block page alignment increases KV pool demands. The remaining after loading weights wasn't enough. When I tried to increase the target to 0.85, the free-memory check failed because the 4B model was already occupying .
The Critical Realization:
gpu_memory_utilizationis a fraction of total GPU memory,not free memory.
To avoid OOMs (Out of Memory) or KV starvation, the sum of all co-resident vLLM utilization fractions must be to account for CUDA framework overhead.
Attempt 2: The Tool-Call Failure
Once the models were resident, Hermes encountered a functional bug: tool calls were returning as plain text. Both hermes_tool_parser.py and qwen3xml_tool_parser.py expect a singular <tool_call> tag, but the model was outputting reasoning inside <think> tags and concluding without the actual call.
I discovered that Qwen3-Next-80B-Thinking only supports thinking mode; enable_thinking: false is a structural no-op. This breaks any SDK relying on tool_choice: auto.
The Fix:
I launched the model with the following flags:
--enable-auto-tool-choice --tool-call-parser hermes (and specifically no --reasoning-parser).
This allowed three LiteLLM aliases (writer, reviewer, and sources) to successfully return finish_reason: tool_calls.
Attempt 3: The Stability Crash
The Reviewer agent required a context window. This triggered a restart loop for the 4B model (19 times!). The 80B model, at 0.85 utilization, was actually occupying , leaving the 4B model with insufficient room to meet its own 0.12 target.
The Final Adjustment:
- 80B Model: Toned down to
gpu_memory_utilization: 0.80. - 4B Model: Dropped to
0.10utilization,max_model_len: 16384, andmax_num_seqs: 8.
I had to lower the 4B's context length because a 0.10 allocation only leaves for the KV pool. A sequence requires , but fits at .
The Residency Math
Here is the data I should have compiled from the start:
| Model | Target Util | Actual Residency | Max Model Len | Max Seqs |
|---|---|---|---|---|
| Qwen3-80B | 0.80 | |||
| Qwen3-4B | 0.10 |
Key Observations:
- The Cushion: The 80B model at
0.80ran under its allocation. This buffer is the only reason the 4B model doesn't crash during variability. - Overhead: The 4B model's actual residency () is higher than the target (). CUDA framework overhead is a constant, regardless of model size.
- Mamba vs. Attention: On
Qwen3-Next, the memory demand for is driven by Mamba state alignment, not standard attention KV. Halving the length does not linearly halve the memory demand.
Final Insights & Playbook
The core takeaway is that gpu_memory_utilization is merely a starting snapshot. Actual residency is the only ground truth.
The Co-residency Playbook:
- Load the largest model first.
- Allow it to stabilize.
- Run
nvidia-smito determine the actual memory used. - Calculate the remaining free pool.
- Size the smaller model's
gpu_memory_utilizationagainst that free pool, subtracting for framework overhead.
🚨 24-Hour Action Item
If you are running a vLLM deployment, execute this command immediately:
nvidia-smi --query-gpu=memory.used --format=csv
Compare this actual number to your gpu_memory_utilization target.
- Check: Does the actual residency diverge from the target by ?
- Action: If yes, your sizing model is incorrect. Fix it before deploying agent stacks or fallback chains to avoid silent failures.