Krea 2: SOTA open-weights 12B image model
Krea 2: A State-of-the-Art 12B Open-Weights Image Model
Technical Report | Published June 23, 2026
Authors: Sangwu Lee, Erwann Millon, Le Zhuo, et al.
🌟 Introduction
In recent years, the landscape of image synthesis has evolved rapidly. Modern flow-matching and diffusion frameworks can now produce high-fidelity images with precise structural stability, legible text, and deep world knowledge. These leaps are the result of a synergy between scalable transformer architectures, sophisticated text encoders, and refined post-training workflows.
However, a new problem has emerged: aesthetic convergence. Many top-tier models have been optimized for reliability, leading them to produce a narrow, "polished" default style. While useful for production, this limits creative exploration. Artists often need to navigate various moods, compositions, and styles rather than receiving a single, standardized output.
The Krea 2 Vision
Krea 2 is designed as a foundation model for exploratory generation. The goal is to create a system that is both expressive (spanning a vast array of aesthetics) and steerable (allowing users to navigate that space precisely).
To achieve this, the team developed a custom large-scale data infrastructure and a distributed training framework. The model utilizes a (12B) parameter count to balance power and efficiency.
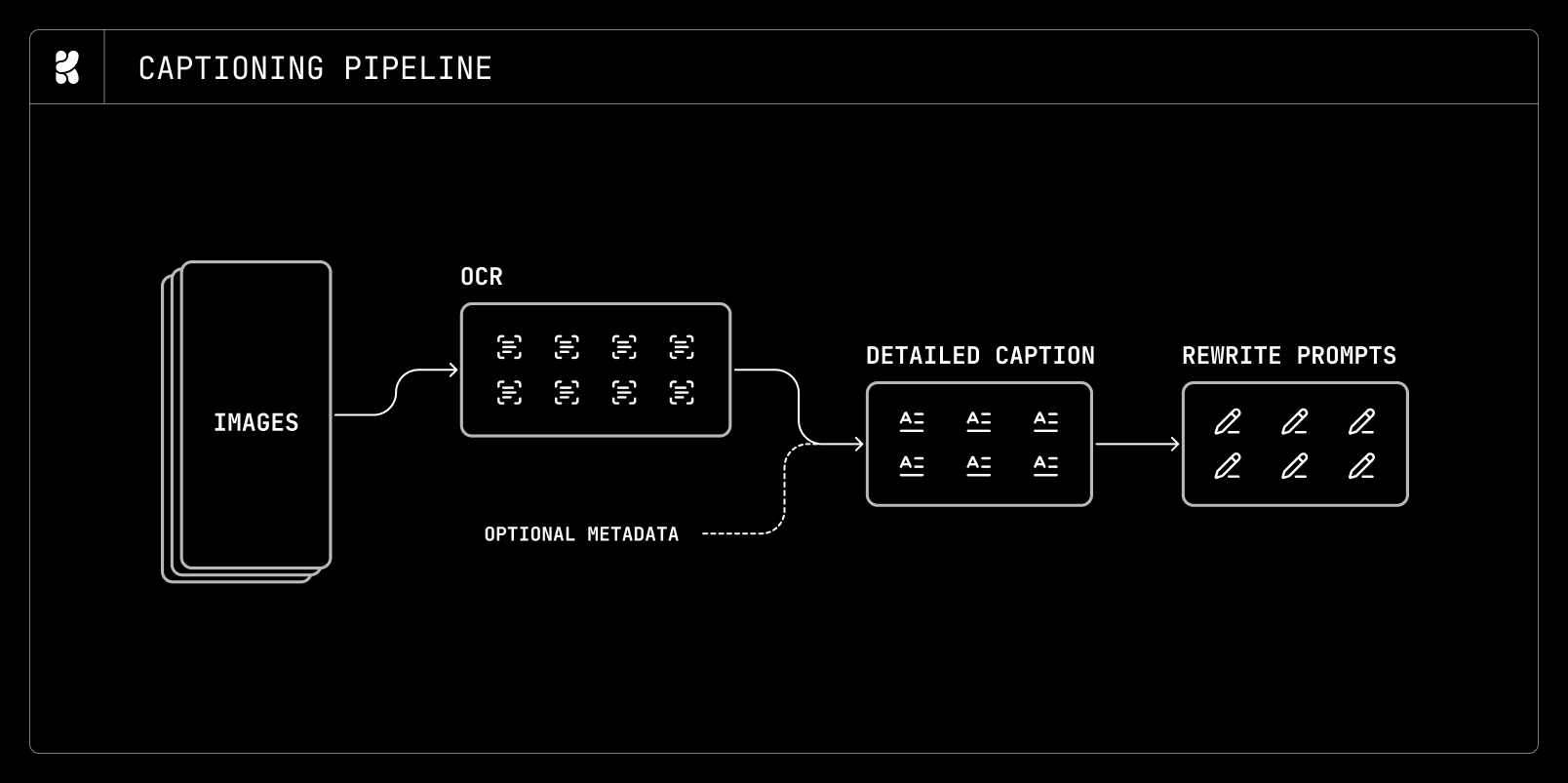
🛠️ Technical Framework
The development of Krea 2 is divided into five primary pillars:
- Data Curation: Principles for maintaining diversity.
- Architecture: A refined Diffusion Transformer (
DiT). - Training Pipeline: A rigorous multi-stage approach.
- Infrastructure: Distributed systems for scale.
- Future Directions: Ongoing research and goals.
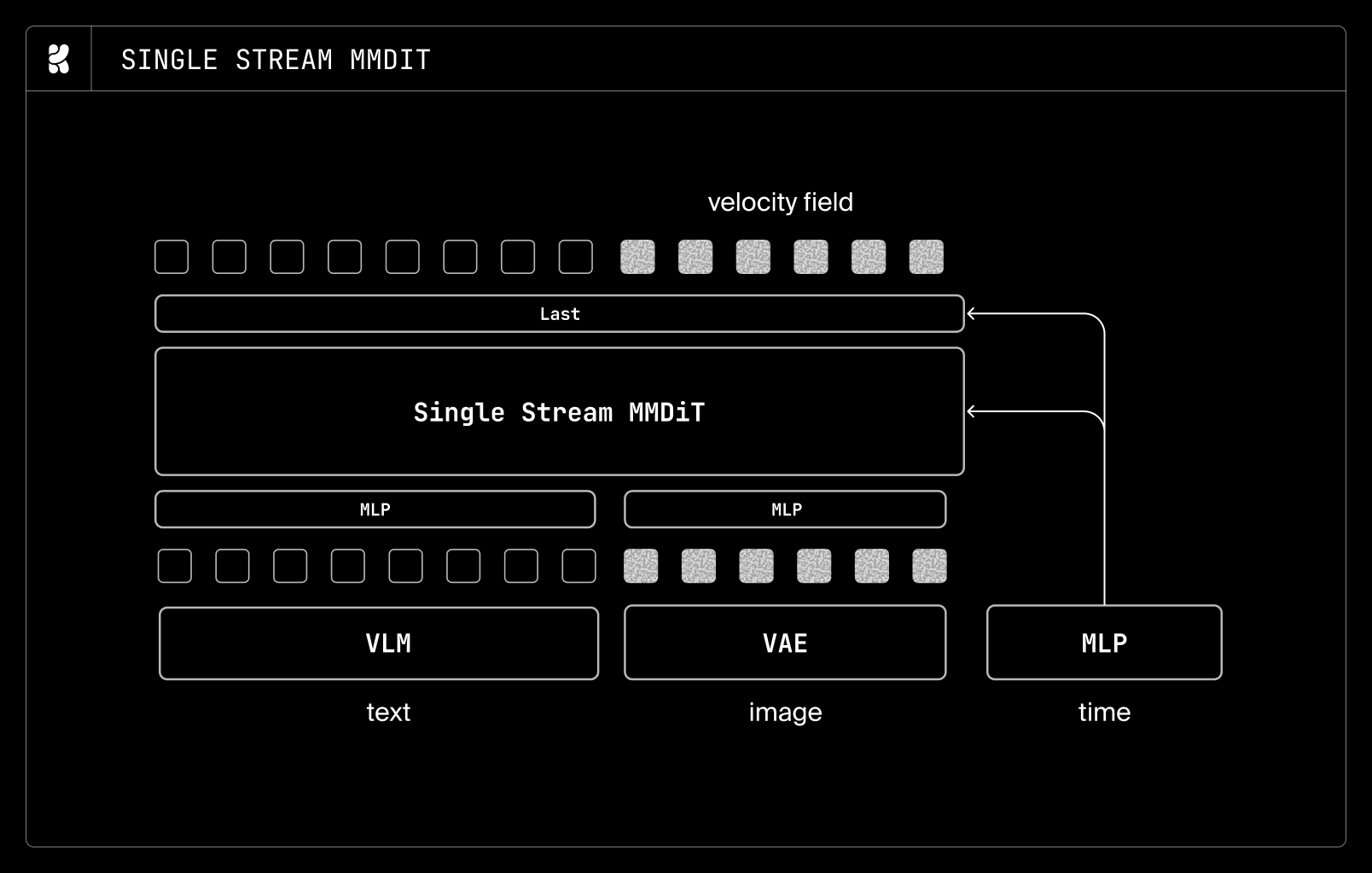
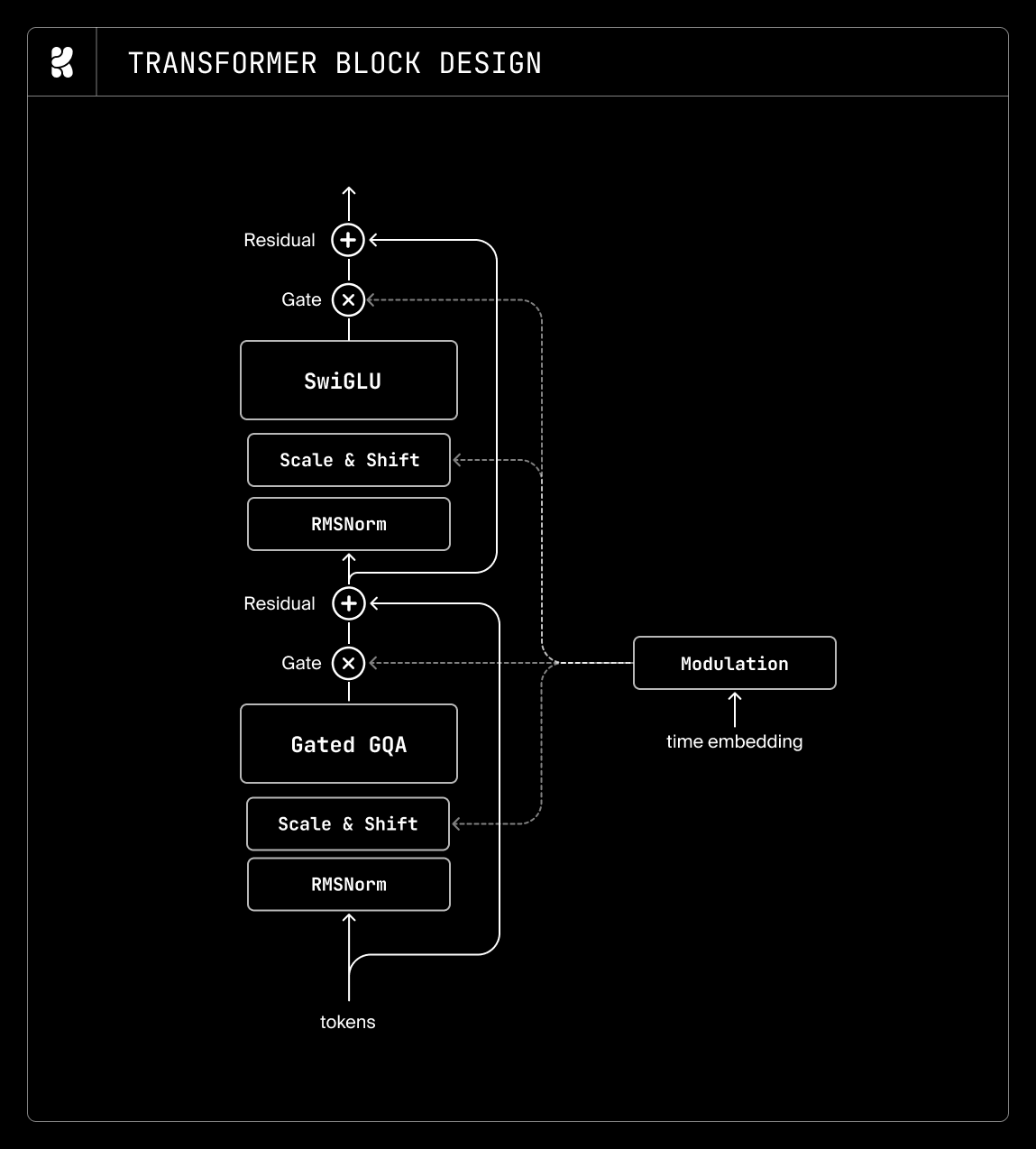
Model Architecture
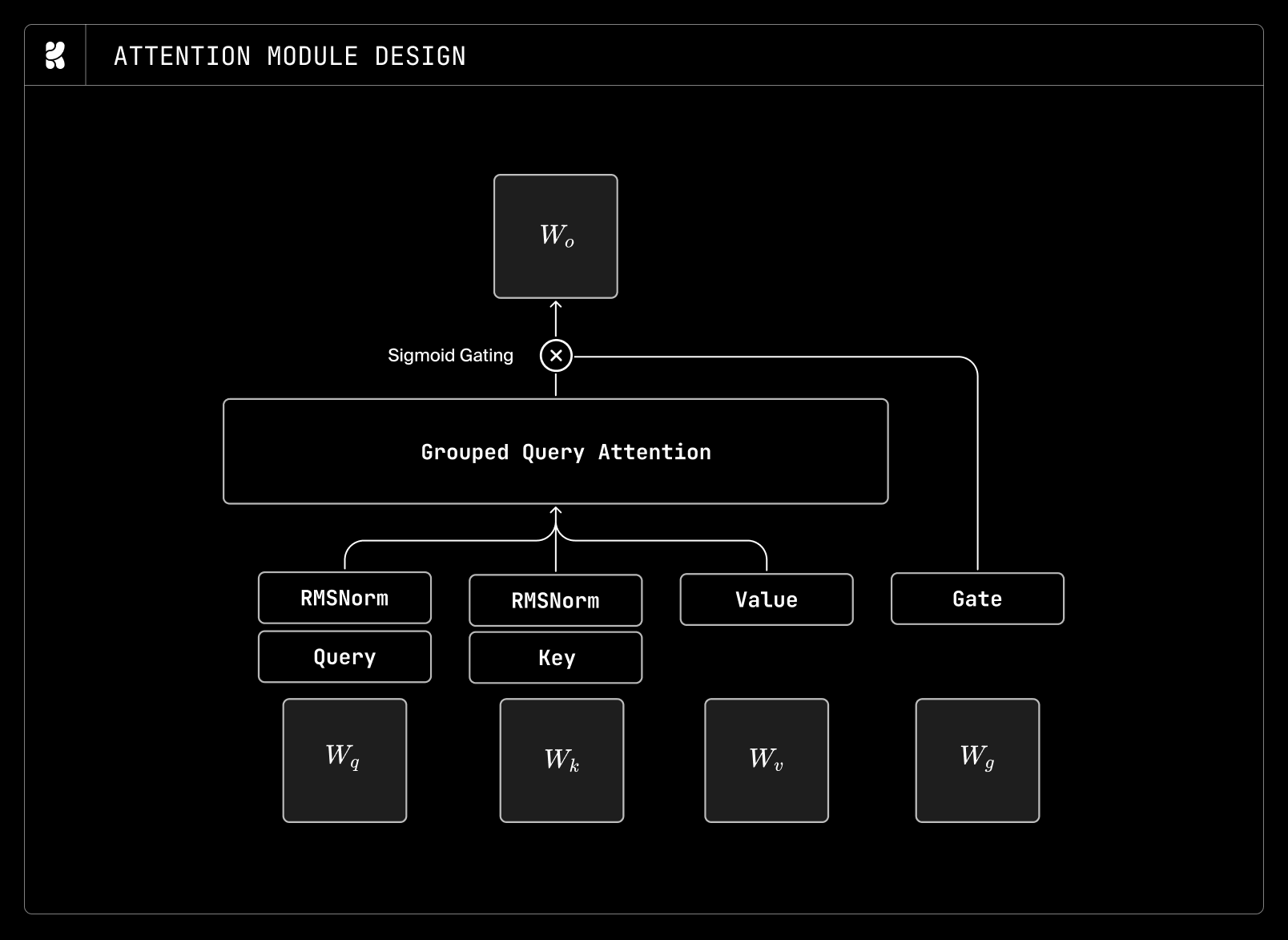
The core of Krea 2 is a performant DiT architecture. Through extensive ablation studies, the team integrated several components to boost stability and convergence speed:
| Component | Purpose | Benefit |
|---|---|---|
| iREPA | Convergence Acceleration | Faster training cycles |
| Qwen3-VL | Text Encoding | Enhanced visual-linguistic understanding |
| GQA | Grouped-Query Attention | Reduced memory overhead/faster inference |
| Sigmoid-Gated Attention | Signal Control | Improved training stability |
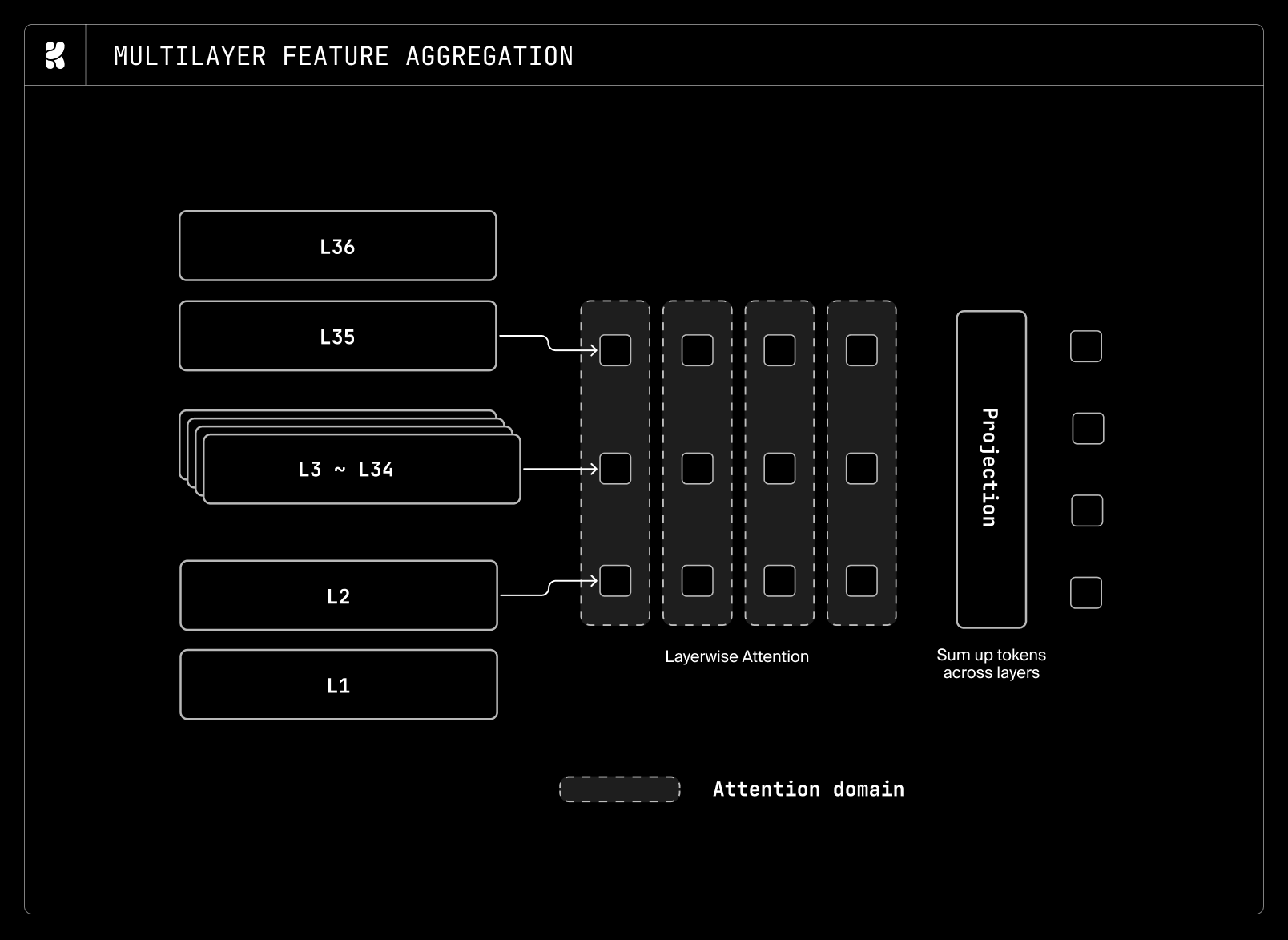
| MFA | Multilayer Feature Aggregation | Better integration of text-encoder features |
Architectural Highlights:
- Lightweight timestep modulation for efficient temporal scaling.
- Improved VAEs for sharper latent representations.
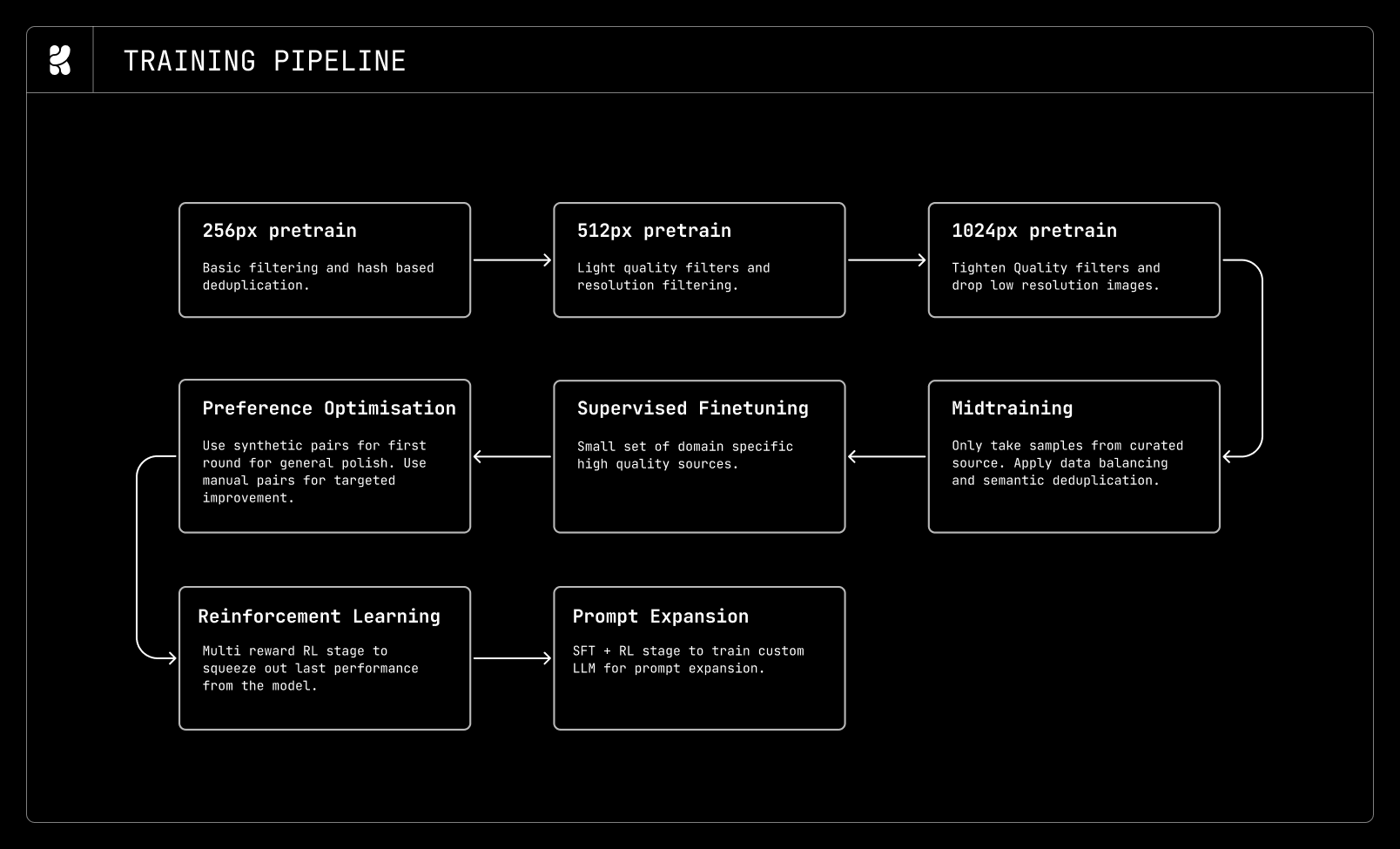
📈 Training Pipeline
Krea 2 does not rely on a single training pass. Instead, it uses a progressive refinement strategy:
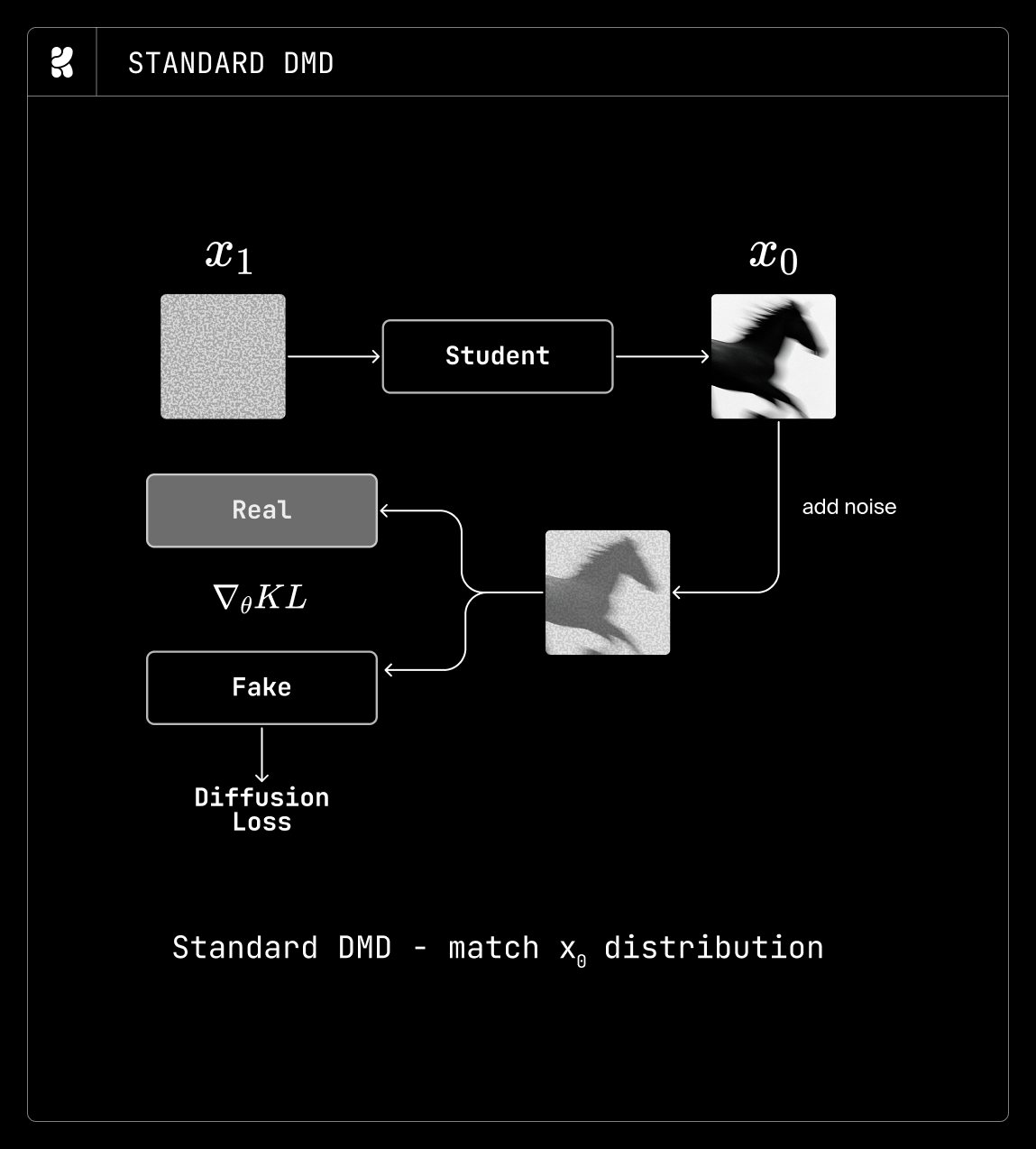
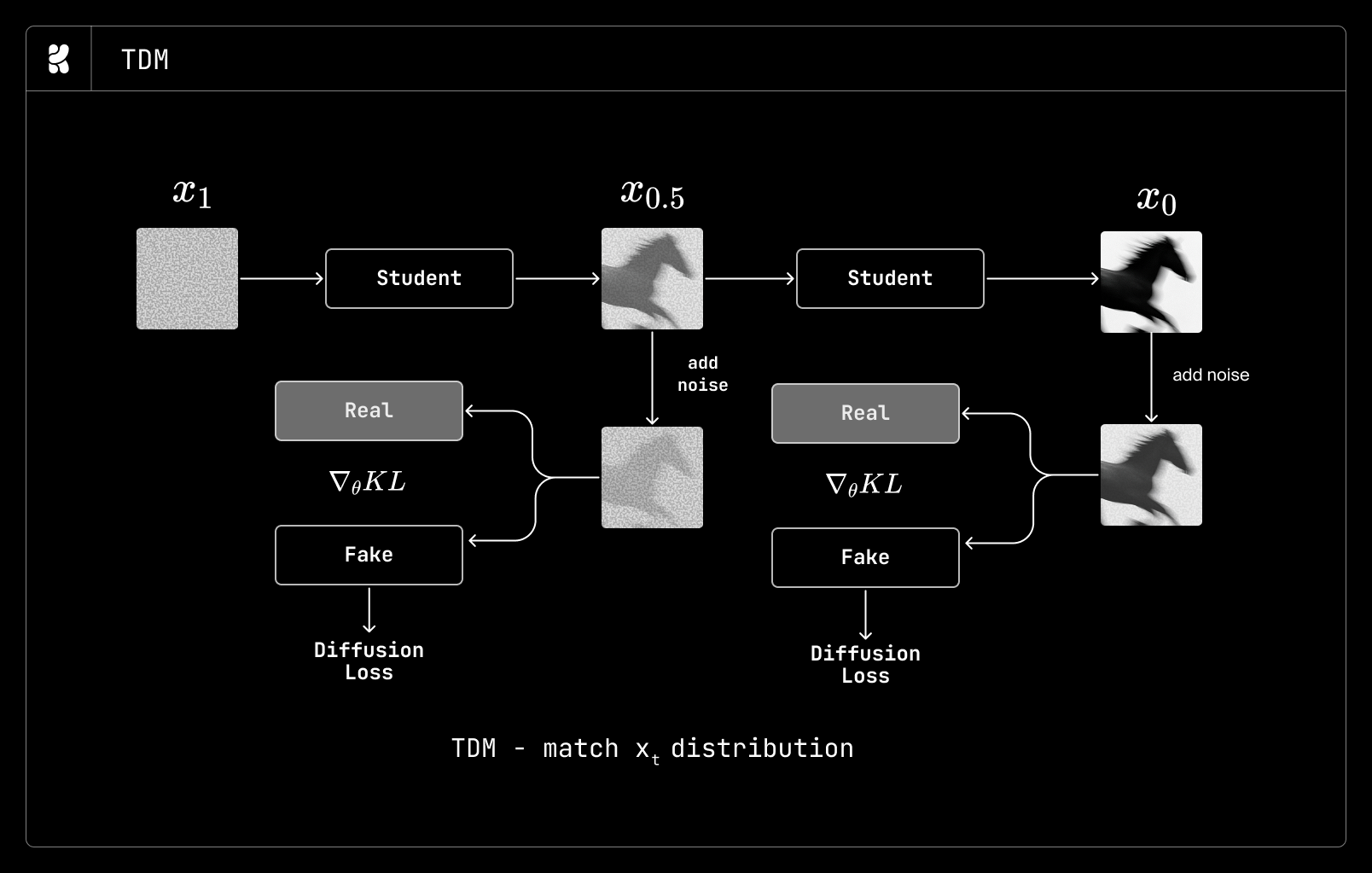
Distillation Techniques
To optimize the model further, the team employed specific distillation methods:
- DMD: Standard distillation for efficiency.
- TDM: A specialized distillation approach for refined quality.
🎨 Steerability & Creative Control
A common gap exists between how a model is trained (using dense, descriptive captions) and how users actually prompt (using short, ambiguous phrases). Krea 2 bridges this gap with two key systems:
1. The Prompt Expander
This system transforms simple user inputs into rich visual descriptions without erasing the original intent.
- Method: Built on open-source LLMs via a two-stage SFT and RL pipeline.
- Goal: Encourage variation and exploration rather than just "beautifying" the image.
2. Style-Reference System
When words fail, users can provide images to guide the aesthetic.
- Minimal Content Leakage: It captures the mood and style without blindly copying the objects in the reference image.
- Fine-grained Control: Users can adjust style strength and mix multiple reference images using weighted averages.
📊 Data Curation Philosophy
Krea 2 rejects the industry trend of aggressive aesthetic filtering.
"Conventional model-based filtering... introduces implicit biases. For example, such methods may classify a blurry image as low quality, even though motion blur or softness can be a deliberate artistic choice."
The team's approach is summarized as follows:
Filter by aesthetic score onlyPrioritize descriptive accuracy.- If a caption accurately describes an image, that image is valuable, regardless of whether it fits a "standard" definition of beauty.
🚀 Performance & Infrastructure
Krea 2 is highly competitive, ranking in the Top 10 on the Artificial Analysis text-to-image leaderboard and taking 2nd place among independent research labs.
To maintain this performance, the team monitored hardware metrics closely to ensure stability during the massive 12B parameter training runs.
Project Checklist & Status
- Distributed training framework built from scratch.
- Multi-stage pipeline (Pretraining RL) completed.
- Open-weights release under permissive license.
- Future work on expanded modality support.
Availability:
- Weights: Hugging Face
- Code: GitHub